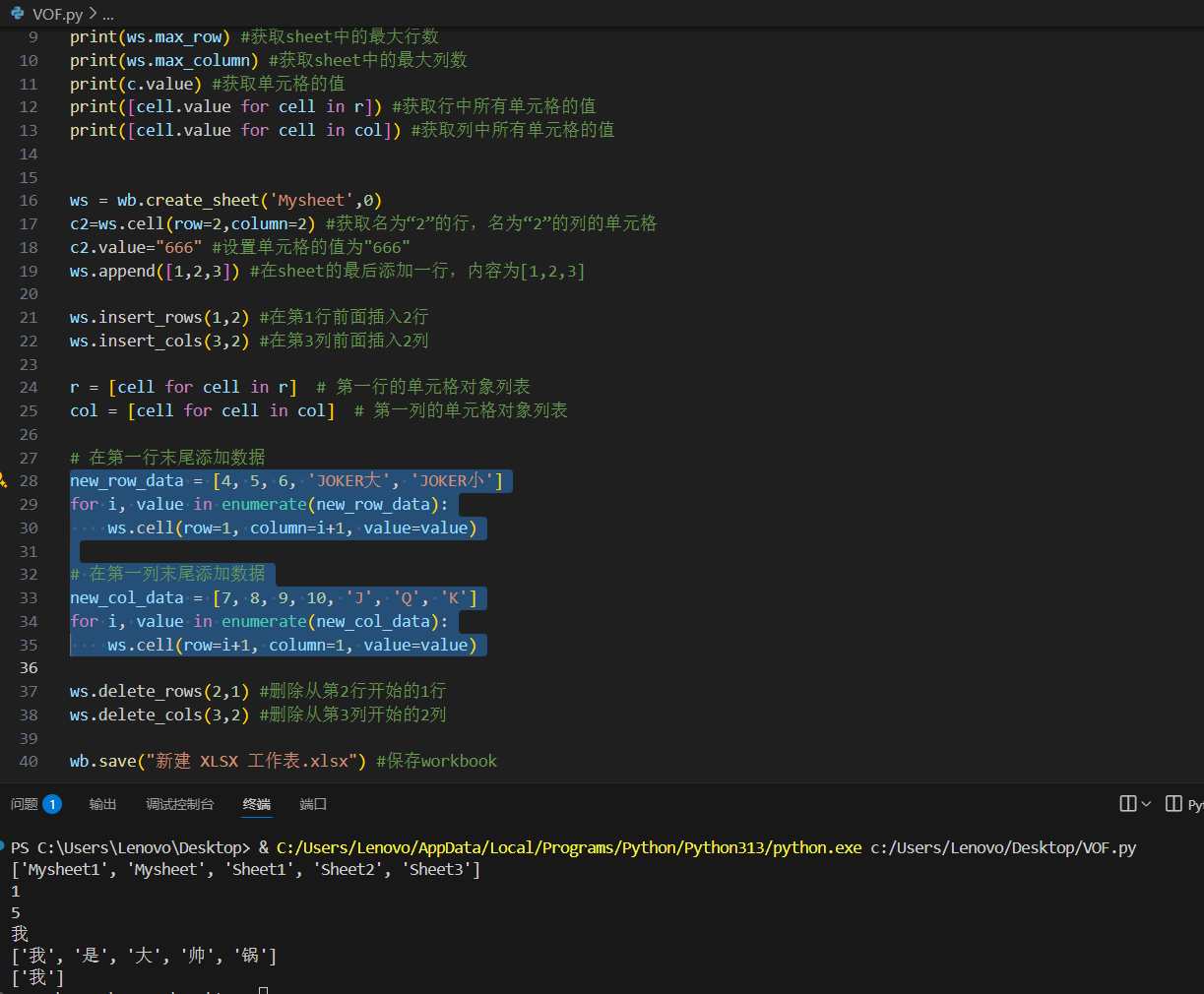
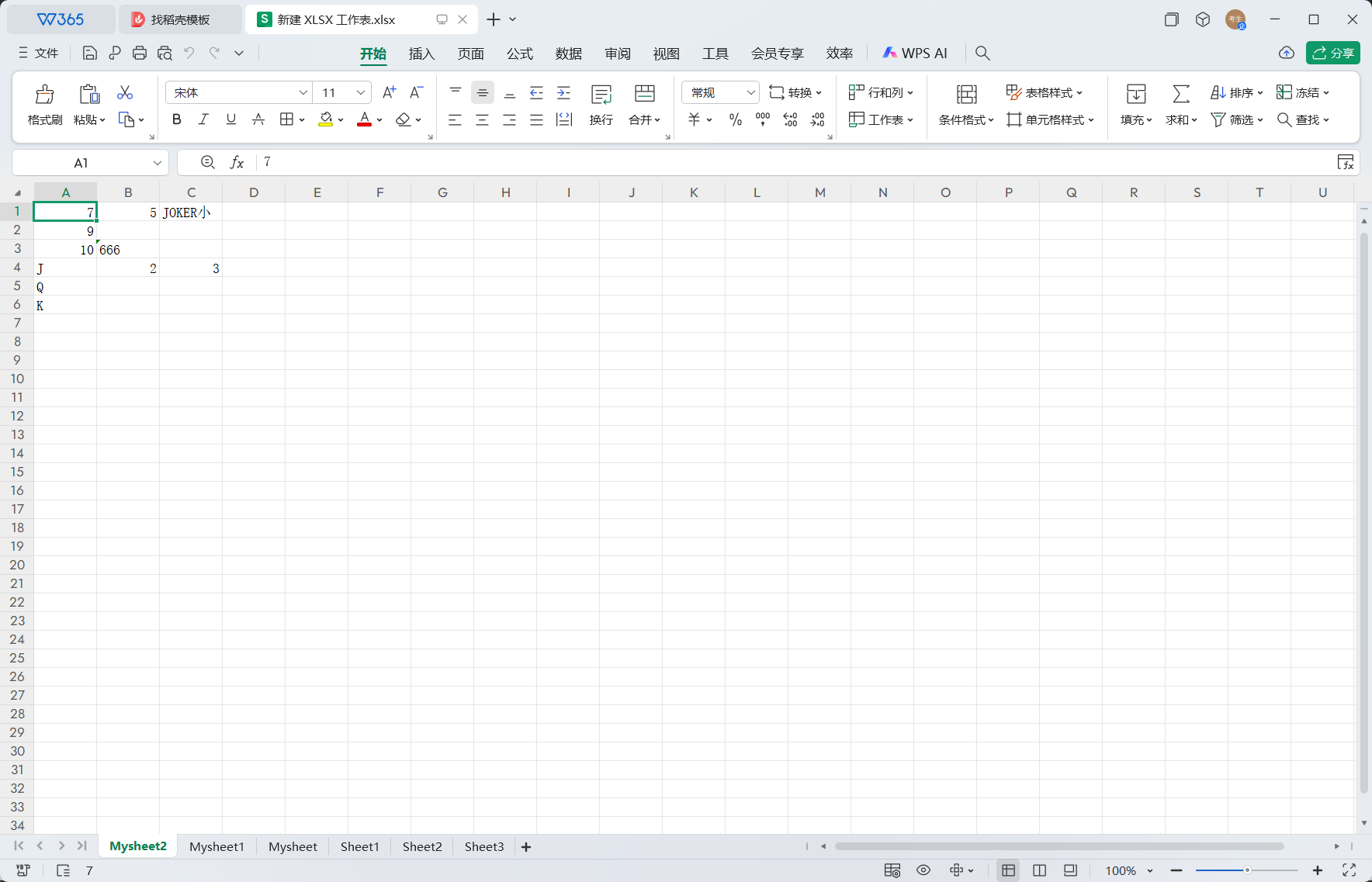
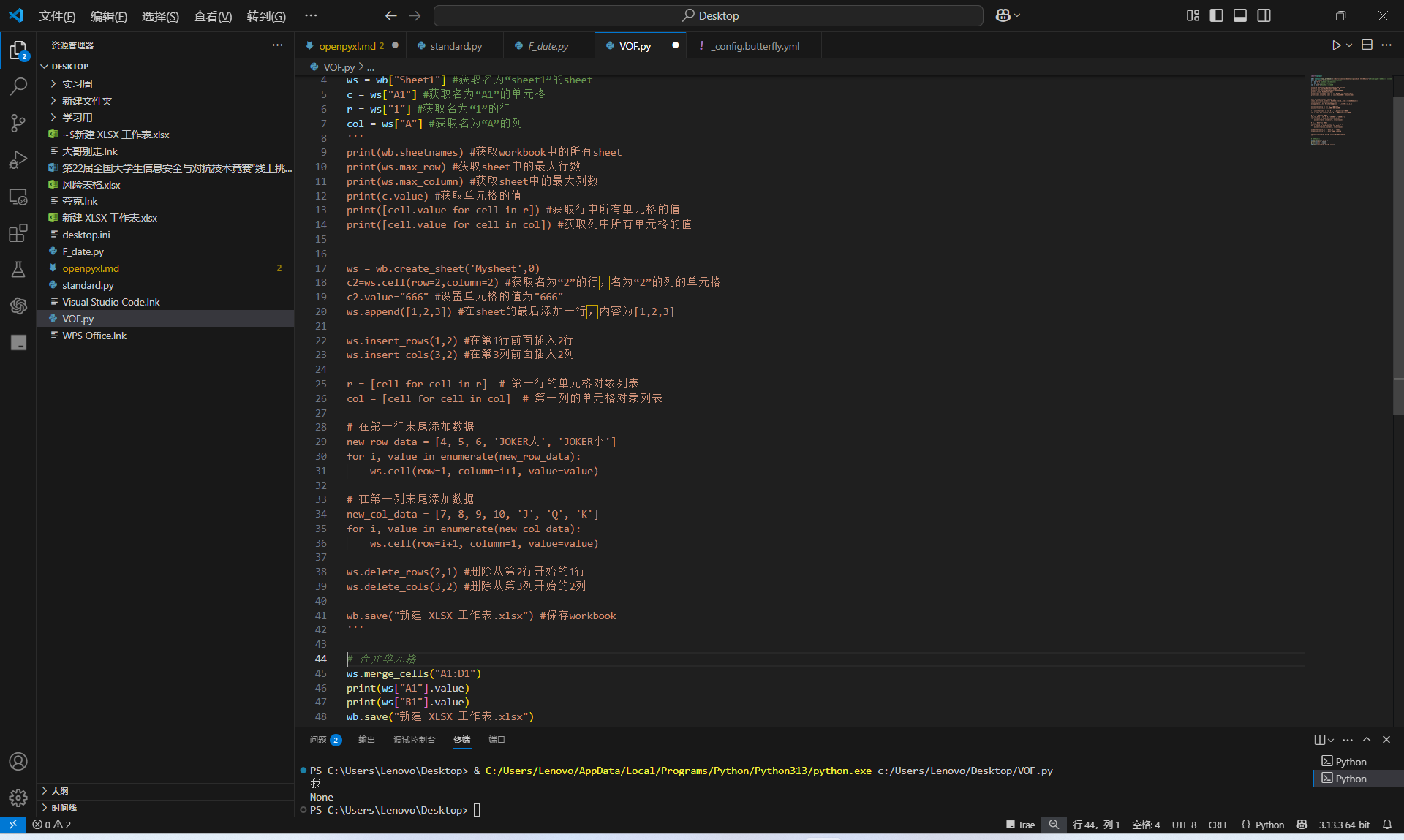
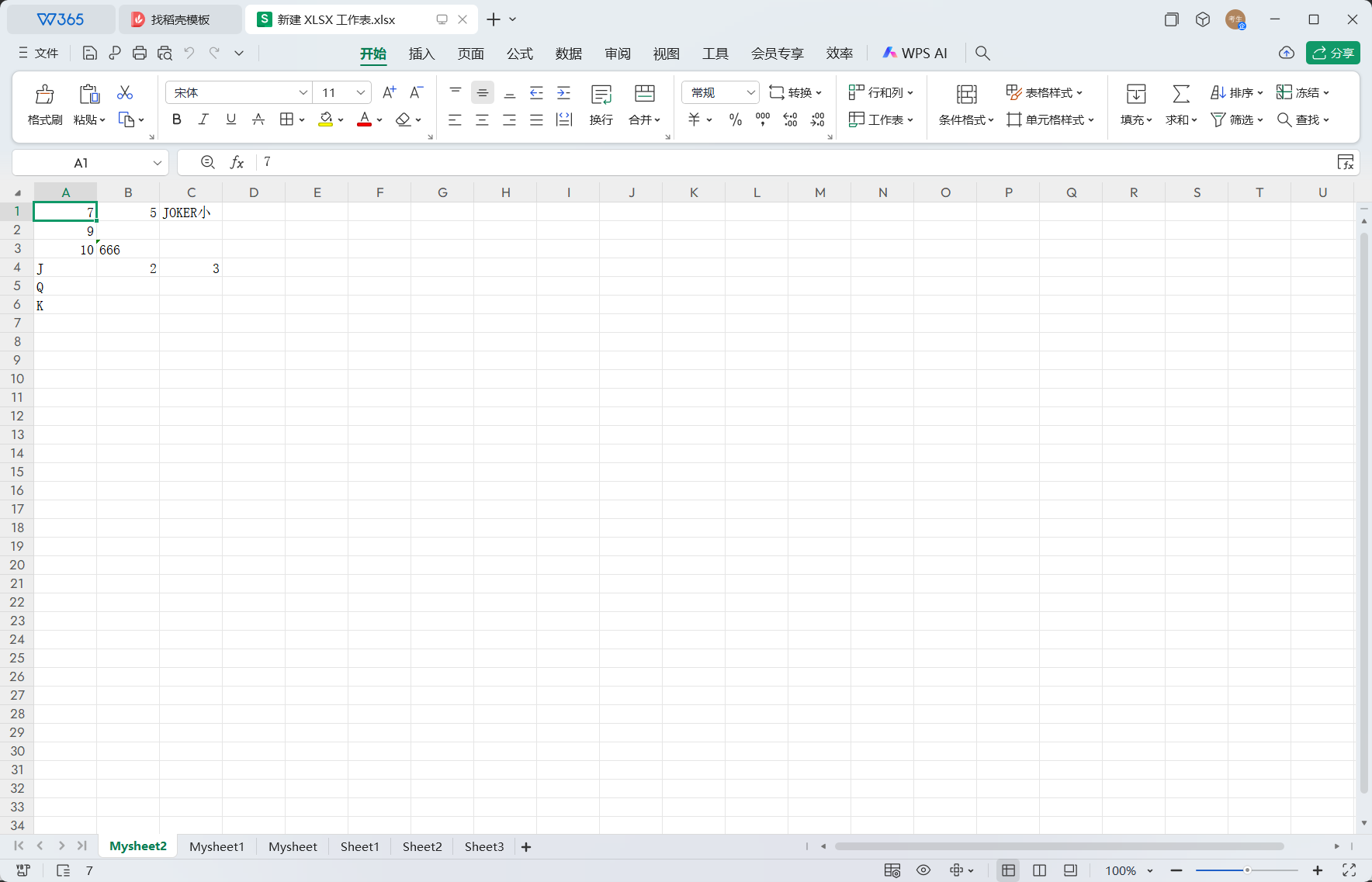
from openpyxl import * defaverage(ws,data,per,row): return ws.cell(row=row,column=(ws.max_column+1),value=round(float(data/per), 2)) # 平均值函数
defadd(ws,row,min_col,max_col): result = 0.00 for col in ws.iter_cols(row, row, min_col, max_col): for c in col: if c.value isNone: c.value = 0.00 result += c.value return ws.cell(row=row, column=(ws.max_column + 1), value=round(float(result), 2)) # 求和函数
from openpyxl import * defchange(ws): for row in ws.rows: for c in row: if c.value=='学号': col=c.column row=c.row break if row and col: break
school_number=[] for r in ws.iter_rows(min_row=row+1,min_col=col,max_col=col,max_row=ws.max_row): for c in r: school_number.append((c.value,c.row))
sort_data=sorted(school_number, key=lambda x: x[0]) sort_row=[item[1] for item in sort_data] new_row = [] for row_num in sort_row: new_row.append([cell.value for cell in ws[row_num]])
for row in ws.iter_rows(min_row=row+1, max_row=ws.max_row): for cell in row: cell.value=None
for index,row_data inenumerate(new_row, start=row+1): for col_index, value inenumerate(row_data, start=1): ws.cell(row=index, column=col_index, value=value) return ws defget_work(path): wb=load_workbook(path) ws=wb.active ws=change(ws) col=ws.max_column return wb,col,ws defget_name(path): wb,col,ws=get_work(path) name=[] for row in ws.rows: for c in row: if c.value=='姓名': col=c.column row=c.row break if row and col: break for r in ws.iter_rows(min_row=row+1, min_col=col, max_col=col, max_row=ws.max_row): for c in r: name.append(c.value) return name defget_number(path): wb,col,ws=get_work(path) number=[] for row in ws.rows: for c in row: if c.value=='学号': col=c.column row=c.row break if row and col: break for r in ws.iter_rows(min_row=row+1, min_col=col, max_col=col, max_row=ws.max_row): for c in r: number.append(c.value) return number defget_score(path): wb,col,ws=get_work(path) score=[] for row in ws.rows: for c in row: if c.value=='总成绩': col=c.column row=c.row break if row and col: break for r in ws.iter_rows(min_row=row+1, min_col=col, max_col=col, max_row=ws.max_row): for c in r: score.append(c.value) return score
from openpyxl import * from openpyxl.styles import Alignment from function_one import average, add from function_two import get_name, get_number, get_score defnew_work(): wb=Workbook() ws=wb.active ws.merge_cells('A1:F1') ws['A1']='平均成绩表' ws['A1'].alignment = Alignment(horizontal='center', vertical='center') ws.append(['姓名','学号','作文平均分','期末听力','期末成绩','总分']) return wb,ws defwrite_data(ws, name, number, score): for i inrange(len(name)): ws.append([name[i], number[i], None, score[i]]) return ws defwrite_average(ws,score): per = len(score) for row in ws.iter_rows(min_row=2, max_row=ws.max_row): for cell in row: if cell.value == '作文平均分': col = cell.column row = cell.row break if row and col: break for i inrange(len(score[1])): data = 0 for j inrange(len(score)): data += score[j][i] average(ws, data, per, row) return ws defwrite_sum(ws): for row in ws.iter_rows(min_row=2, max_row=ws.max_row): for cell in row: if cell.value == '总分': col_all = cell.column row_all = cell.row break if cell.value == '作文平均分': col_wri = cell.column row_wri = cell.row break if row_wri and col_wri and row_all and col_all: break for i inrange(row_all+1, ws.max_row + 1): add(ws, i, col_wri, col_all) return ws defmain(path1,path2,path3,path4,path5): print("请cray老师把四次作文成绩放到前四个,把听力成绩放到第五个") name=[] name=get_name(path1) number=[] number=get_number(path1) score=[get_score(path1),get_score(path2),get_score(path3),get_score(path4)] wb,ws=new_work() liston=[] liston=get_score(path5) ws=write_data(ws, name, number, liston) ws=write_average(ws, score) ws=write_sum(ws) wb.save("成绩汇总.xlsx")